Mdps The Value Function
Mdps The Value Function Information Guide
Introduction on Mdps The Value Function

Returning to the Markov Decision Process, this time with a solution. Nick Hawes of the ORI takes us through the algorithm, strap in ... 0.1 is the probability of transitioning to that state and then the reward again is going to be zero and the Here we introduce dynamic programming, which is a cornerstone of model-based reinforcement learning. We demonstrate ... For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ... Deterministic route finding isn't enough for the real world - Nick Hawes of the Oxford Robotics Institute takes us through some ... For more information about Stanford's Artificial Intelligence professional and graduate programs, visit:
In this video, you'll get a comprehensive introduction to Markov Design Processes. This video is part of the Udacity course "Reinforcement Learning". Watch the full course at Dive into the core concepts of Reinforcement Learning! This video breaks down Markov Decision Processes (
Main Features
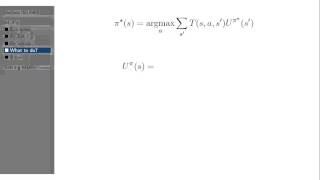
Developments










Detailed Analysis
Data is compiled from public records and verified media reports.
Last Updated: June 21, 2026
Future Outlook

Disclaimer: Disclaimer: Details estimates are based on publicly available data, media reports, and financial analysis. Actual numbers may vary.












