Overview on Gradient Accumulation Principles And Code
How much is Gradient Accumulation Principles And Code worth? We've compiled comprehensive wealth data, income records, and financial insights for Gradient Accumulation Principles And Code. Explore the complete Details breakdown, salary history, and asset portfolio.
Batch size is one of the most important hyperparameters in deep learning training and has a major impact on the accuracy and ... AIResearch The video lecture discusses how to train a large model on ... * Collaboration inquiries: commit.im.com (Please refrain from using personal emails; this email address is for business ... Get Free GPT4.1 from Okay, let's dive deep into understanding and fixing issues related to
Main Features
Explore the primary sources for Gradient Accumulation Principles And Code.
Latest News
Stay updated on Gradient Accumulation Principles And Code's newest achievements.
ViZDoom 10: Results from gradient accumulation experiments
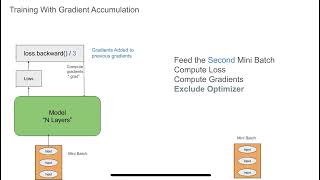
Gradient Accumulation
gradient accumulation in pytorch
What is Gradient Accumulation and How do we Address it in PyTorch?
What is Gradient Accumulation and Gradient Clipping?
Gradient Accumulation
Gradient Descent in 3 minutes
Three Perspectives on Gradient Descent (And You Only Know One)
fixing faulty gradient accumulation understanding the issue and its
Deep Dive
Data is compiled from public records and verified media reports.
Last Updated: June 14, 2026
Future Outlook
For 2026, Gradient Accumulation Principles And Code remains one of the most searched-for information profiles. Check back for the newest reports.
Disclaimer: Disclaimer: Details estimates are based on publicly available data, media reports, and financial analysis. Actual numbers may vary.