Efficient Compression Of Large Language
Efficient Compression Of Large Language Information Guide
Background of Efficient Compression Of Large Language

The podcast discusses a paper that introduces LLM-Pruner, a task-agnostic framework for Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Learn in-demand Machine Learning skills now → Learn about watsonx → In this video, we break down knowledge distillation, the technique that powers models like Gemma 3, LLaMA 4 Scout & Maverick, ... In this episode of the AI Research Roundup, host Alex explores a cutting-edge paper on Want your team maximizing Claude? I run 1:1 and team AI workshops for companies doing $1M+ per year: ...
A light intro to LLMs, chatbots, pretraining, and transformers. Dig deeper here: ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Four techniques to optimize the speed ... Download Tanka today and enjoy 3 months of free Premium! You can also get $20 / team for each referrals ...
Key Details

Recent Updates






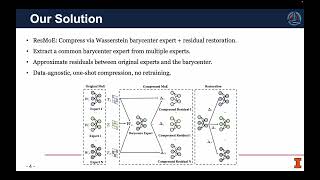



Full Guide
Data is compiled from public records and verified media reports.
Last Updated: June 7, 2026
Final Thoughts

Disclaimer: Disclaimer: Details estimates are based on publicly available data, media reports, and financial analysis. Actual numbers may vary.












